

Introducing Mistral OCR 4. It creates structure with bounding boxes, block classification, and inline confidence scores in 170 languages. 🧵👇 https://t.co/jR78NkL4xK
Jun 23, 2026
Views1.28M
Comments208
Reposts481
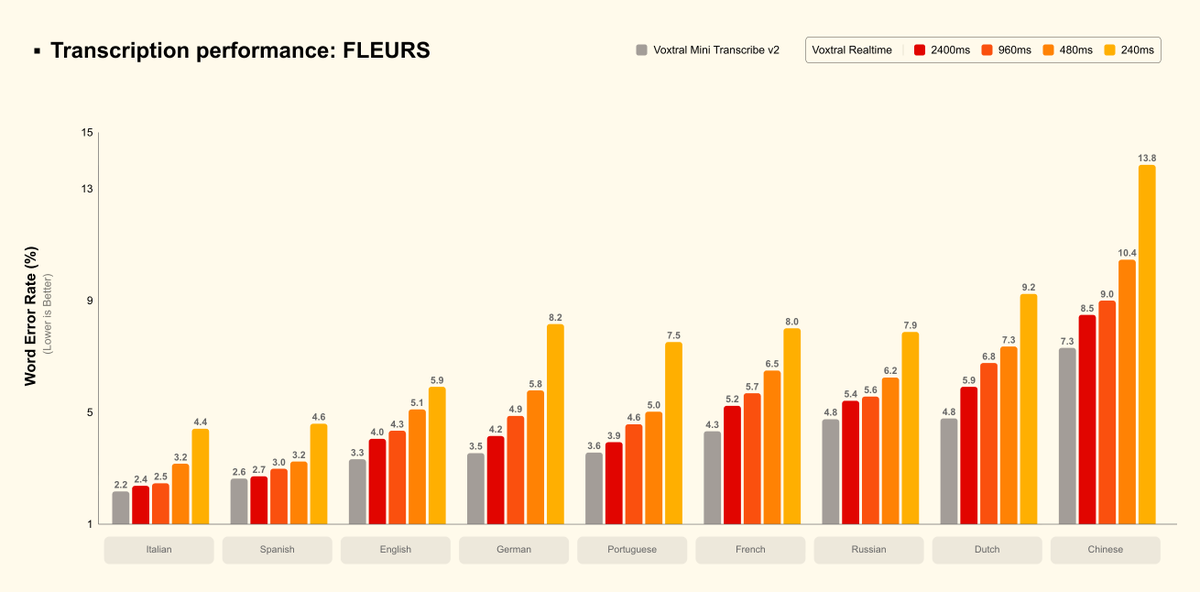
Voxtral Realtime is built for voice agents and live applications. Its natively streaming architecture delivers latency configurable to sub-200ms. And at 480ms, it stays within 1-2% WER of our offline model. We release the model as open weights under Apache 2.0. https://t.co/sZwzCDd4tu
Introducing Mistral OCR 4. It creates structure with bounding boxes, block classification, and inline confidence scores in 170 languages. 🧵👇 https://t.co/jR78NkL4xK

🔊Introducing Voxtral TTS: our new frontier open-weight model for natural, expressive, and ultra-fast text-to-speech 🎭Realistic, emotionally expressive speech. 🌍Supports 9 languages and accurately captures diverse dialects. ⚡Very low latency for time-to-first-audio. 🔄Easily https://t.co/Q2mdo8UBVo

Introducing Voxtral Transcribe 2, next-gen speech-to-text models by @MistralAI. State-of-the-art transcription, speaker diarization, sub-200ms real-time latency. Details in 🧵 https://t.co/0IeiJOpiAZ

Today, we’re introducing Forge, a system for enterprises to build frontier-grade AI models grounded in their proprietary knowledge. 🌎 Forge bridges the gap between generic AI and enterprise-specific needs. Instead of relying on broad, public data, organizations can train models https://t.co/4YQ3ADvixr